Appeared in: Journal of the American Society for Information Science (JASIS), November, Vol. 48, No. 11, pp. 987-1003.
Brian R. Gaines, Lee Li-Jen Chen and Mildred L. G.
Shaw
Knowledge Science Institute
University of Calgary
Alberta, Canada
T2N 1N4
{gaines, lchen,
mildred}@cpsc.ucalgary.ca
http://ksi.cpsc.ucalgary.ca/KSI/
The Internet (the net) and World Wide Web (the web) have grown rapidly in the past decade and have come to play a major role in supporting discourse and publication in scholarly communities. The development and application of new services has been very rapid with little central planning, and, despite the widespread use, there is little information as yet on the human factors of the use of the net and web. In particular, models of the human factors of individuals interacting with workstations have to be extended to take into account the essential social aspects of computer-mediated discourse and publication. This article provides a framework for analyzing the utility, usability and likeability of net and web services, and illustrates its application to significant aspects of supporting scholarly communities. The utility of the net and web are measured in terms of the growth of usage, and the different services involved are distinguished in terms of their specific utilities. A layered protocol model is used to model discourse through the net, and is extended to encompass interaction in communities. An operational criterion for distinguishing different communities is defined in terms of the types of awareness that resource providers and users have of one another. A temporal model of discourse processes is developed that enables the spectrum of services ranging from real-time discourse to long-term publication to be analyzed in a unified framework. The dimensions of awareness and time are used to characterize and compare the full range of net services, and model their unification through the next generation of web browsers.
Widely available access to the Internet is already having a major impact on scholarly publishing (Gaines, 1993a; Harrison and Stephen, 1995; Peek and Newby, 1996). The World Wide Web can mimic existing paper publications in the presentation of typographic text, diagrams and photographic materials. The documentation preparation costs are similar to those for paper, and documents are readily made available on the net for world-wide access at low cost (Ford, Makedon and Rebelsky, 1995). The cost of production and dissemination of digital publications is also substantially lower than that of paper publications leading to predictions of the demise of paper journals on economic grounds alone (Odlyzko, 1995). The impediments to electronic publication supplanting paper publication are primarily the sociological ones of scholarly communities providing a supporting infrastructure in terms of quality control and well-defined publication procedures and long-term access guarantees (Gaines, 1995).
However, the net and web offer a new medium for scholarship that goes beyond the mimicry of paper publication. Digital publication provides facilities that greatly improve on paper publication, such as making color freely available, supporting multimedia video and sound, and allowing datasets and programs to be included which may be accessed interactively and support animation, simulation and the independent reproduction of analyses (Claerbout, 1992). In addition, since the publications are computer-readable and accessible the digital medium makes possible automatic indexing through content analysis. There are also social innovations in publishing which attempt to combine informal and formal publishing such as InterJournal (Redi and Bar-Yam, 1995), a technology for refereed journals whereby articles remain distributed at author sites but are indexed through virtual journals in a system that makes publication a continuum of continuing assessment and annotation.
While the use of the net to access documents is significant in its impact on scholarly publication, computer-mediated communication is also having an impact on the nature of scholarship itself. Over the last 300 years scholarly journals, books and conference proceedings have become the primary media for recording the products of scholarship as what Popper (1968) terms "world 3" objects, the expressed products of the human mind that continue to exist independently of their originators. Published scholarship has been the foundation of the post-enlightenment growth of knowledge, and it has become standard to model the structure of scholarship itself in terms of the flow of publications (Crane, 1972). However a new medium not only enhances the old but also retrieves that which was previously obsolesced (McLuhan and McLuhan, 1988). The ease of conversational interaction on the net is reintroducing a form of oral discourse in which members of a scholarly community can communicate privately and publicly, informally or formally, with a rapid turnaround approaching that of conversation, time to reflect on replies if wished, and an electronic archive of the discourse if required.
Social and anthropological studies of the behavior of scholars show that the highly refined and censored products that are published do not capture the processes of knowledge formation (Mitroff, 1974). It is possible that the emphasis on the formal publication as the main medium of knowledge has arisen because there has been no convenient way to capture the actual discourse of scholarship. When this is possible, for example in the Peirce-Welby, Russell-Jourdain or Born-Einstein correspondences, the resultant literature is very insightful. As scholarly discourse increasingly takes place through computer-mediated communication, and the discussion can be archived, indexed and made available, it is possible that the discourse itself will be seen to be as important a "world 3" product as its occasional formalization into a paper.
Thus, the net is not only significant in supporting scholarly interaction with no impediment of distance or cost, but also in supplementing the publication of works in the formal rhetoric of a particular scholarly sub-discipline with less formal discourse. Indeed, if one looks more deeply into the social needs satisfied by books and journals, it may become more effective to answer questions not by searching for knowledge in publications but, more simply, by asking the question on the net. As prophesied in the early days of timeshared computing:
"If fifty percent of the worlds population are connected through terminals, then questions from one location may be answered not by access to an internal data-base but by routing them to users elsewherewho better to answer a question on abstruse Chinese history than an abstruse Chinese historian." (Gaines, 1971)
News groups and list servers now operate in precisely the manner suggested, with questions being posed and answers being given by experts in the relevant domain. Research in computational artificial intelligence has had limited success in developing computer-based expert systems (Dreyfus and Dreyfus, 1986). News groups, list servers and corporate memories such as Ackermans (1994) answer garden have the potential to provide human-based expert systems that truly deserve the appellation.
The publication of unrefereed material through list servers and electronic archives may be seen as negative for scholarship because it can by-pass existing quality assurance gatekeepers. However, those authors whose publications are circulated in this way often report that they have received hundreds of critical commentaries, rather than 2 or 3 referees reports, and the quality of the product continually improves as a result of the comments (Floridi, 1995; Odlyzko, 1995). Thus, computer-mediated communication should be evaluated not only as improved support for scholarly discourse but also as having the potential to effect radical changes in the scholarly publication process.
These changes in the processes of scholarship involve a socio-technical system in which rapidly evolving new technologies are being integrated into knowledge processes of human communities that are fundamental to human civilization. The human factors involved are not only those of an individual interacting with a workstation, but also those of loosely defined international scholarly communities, interactions within them, across them, and between them and society at large. New models are required that are rich enough to encompass the psychological, social and technical aspects of the net and web, yet which are specific enough to allow quantitative models to be developed and design policies to be formulated. This article provides a framework for such models.
The Internet standards document, the Request for Comments (RFC) that answers the question "What is the Internet?", offers three different definitions (Krol, 1993):
1 a network of networks based on the TCP/IP protocols,
2 a community of people who use and develop those networks,
3 a collection of resources that can be reached from those networks.
These are complementary perspectives on the net in terms of its technological infrastructure, its communities of users, and their access to resources, respectively. The network perspective emphasizes the telecommunications infrastructure. The community perspective emphasizes human discourse through that infrastructure. The resource perspective emphasizes the human, multimedia and computational resources available to the community through the telecommunications infrastructure. For users of the net and web the primary human factors issues are those that affect individual and community development of, and access to, the networked resources.
A good starting point for a comprehensive analysis of the human factors of the net and web is Shackels (1991) basic factoring of human factors issues into:-
utilitywill it do what is needed functionally?
usabilitywill the users actually work it successfully?
likeabilitywill the users feel it is suitable?
Shackel measures usability on four dimensions:
effectivenessperformance in accomplishment of tasksthe access to potential utility
learnabilitydegree of learning to accomplish tasksthe effort required to access utility
flexibilityadaptation to variation in tasksthe range of tasks for which there is utility
attitudeuser satisfaction with systemthe manifestation of potential likeability
In applying this analysis to the net and web one has to take into account that utility in a collaborative environment is not just for individual users but for communities. For example, the accessibility of a system to all members of the relevant reference community is a utility consideration. One has to take into account that usability is not intensionally defined in terms of compliance with human factors guidelines, but rather extensionally defined in terms of evidence of a high proportion of effective users. Likeability is a critical factor to user adoption of a technology, particularly in a competitive market place, but it is sometimes taken as a "subjective" dimension not subject to formal modeling. Trevino and Webster (1992) developed a formal model of likeability in the context of computer-mediated communication using Csikszentmihalyis (1990) concept of flow underlying the psychology of optimal experience, and Hoffman and Novak (1995) have recently applied it to the analysis of marketing through the web.
It is important to analyze the utility of a technology before one considers its usability. The analysis of what is "needed functionally" is fundamental to understanding the problems users have in fulfilling their needs. The utility of email, for example, often appears so obvious that human factors analysis focuses only on the user interface. However, a deeper analysis of needed functionality will reveal that the support of discourse through a textual medium with no voice intonation, body language, and so on, involves complex human factors issues (Walther, 1992; Spears and Lea, 1994). The fact that the computer interface itself does not specifically support the netiquette (Shea, 1994) problems of electronic discourse does not mean that these problems can be neglected in human factors analyses. Minimally, it draws attention to the need for user guidance or training, and technically it suggests that tools that evaluate email in terms of the emotional loading of the words involved (Whissel, 1989) might be useful to users.
Human factors studies of the net and web have to analyze the social expectations of the community within which the communication takes place, and the users objectives in communicating. The computer system has no technical understanding of these issues, but they determine the utility of a computer-mediated system as much as the lower layers, and failure by users to conform with the cultural norms or express their intentions effectively is failure of usability as much as is pressing the wrong icon to send the mail.
A fundamental measure of utility is the degree to which a technology is utilized. Allens (1977) classic studies suggested that accessibility of an information source exerts a stronger influence on use than its quality, which may explain the massive growth of net and web usage in recent years. It is important to quantify this growth as much as possible to determine the real degree of interest and utilization in objective terms.
The net and web are both technologies that came into being through serendipity rather than design in that the intentions and aspirations of their originators had little relation to what they have become, and standards have been developed by reverse engineering what has come into use (Kahin and Abbate, 1995). As the development of the electronic digital computer can be attributed to needs and funding in the 1940s arising out of the second world war, so can that of the Internet be attributed to needs and funding in the 1960s arising out of the cold war. The Eisenhower administration reacted to the USSR launch of Sputnik in 1957 with the formation of the Advanced Research Projects Agency (ARPA) within the Department of Defense to regain a lead in advanced technology. In 1969 ARPANET (Salus, 1995) was commissioned for research into networking with nodes at UCLA, UCSB and the University of Utah. By 1971 ARPANET had 15 nodes connecting 23 computers and by 1973 international connections to the UK and Norway had been created.
Use of ARPANET by the scientific and engineering communities grew through the 1970s and in 1984 the National Science Foundation in the USA funded a program to create a national academic infrastructure connecting university computers in a network, NSFNET. In 1987 the net had grown to such an extent that NSF subcontracted its operation to Merit and other commercial providers, and in 1993/1994 the network was privatized and its operation taken over by a group of commercial service providers. Email on the Internet commenced in 1972, news distribution in 1979, gopher in 1991, and web browsers with multimedia capabilities in 1993. The growth to over one million nodes, the growing commercial usage of Internet services, and the multimedia capabilities of the web in the 1993/1994 period combined to persuade government and industry that the Internet was a new commercial force comparable to the telephone and television industries, and the concept of an information highway (Burstein and Kline, 1995) came into widespread use.
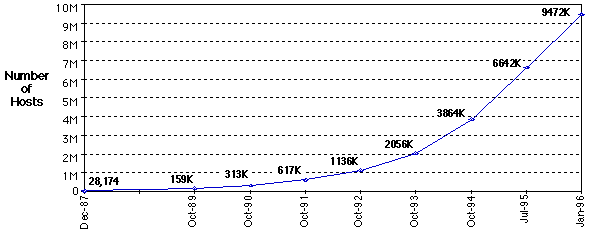
In recent years the number of computers connected through the Internet has grown from some 28 thousand at the beginning of 1988, to over 9 million at the beginning of 1996. Figure 1 shows data plotted from the Internet Domain Surveys undertaken by Network Wizards using a sampling methodology involving checking 1% of machines (NW, 1996). The 1996 figures may be put into perspective by noting that it constitutes one machine on the net for every thousand people on the planet. The growth rate has been consistently some 100% a year so that, if this was sustained, within ten years there would be one Internet computer for each person. The demographics are such that Internet access is heavily biased to the developed world, and there are substantial barriers to access elsewhere (Matta and Boutros, 1989; Kahin and Keller, 1995), but the size and growth rate of the net have already made it a substantial medium for communication. Universities and other research organizations were the primary source of the initial growth, net access became routinely available to scholars in the late 1980s, and to the general public in North America and parts of Europe in the mid 1990s.
Figure 1 Growth in number of hosts on the Internet
It is difficult to estimate the number of users of the net. Multipliers of 10 to 100 were applicable to the number of machines in the early stages of growth, but no longer apply as the computers on the net becoming increasingly workstations or personal computers rather than timeshared mainframes. The number of email users was estimated at some 27 million in October 1994 (IBC, 1995), most of whom would have at least Internet email gateways so that the multiplier then was about 7 to 1 between users and machines. An October 1995 survey (CommerceNet, 1995) estimates that 17% (37M) people aged 16 or above in North America have access to the Internet indicating that the multiplier is remaining at the same level. Some 11% (24M) had used the Internet in the previous 3 months, and the average usage of these users was over 5 hours a week.
Until 1994 the "acceptable use" policy of NSF restricted the use of the net backbone operated by Merit to academic and industrial research stating "NSFNET Backbone services are provided to support open research plus research arms of for-profit firms when engaged in open scholarly communication and research. Use for other purposes is not acceptable." (Aiken, Braun, Ford and Claffy, 1992). Hence, the substantial usage of the net up to the 2 million host level was for scholarly purposes, and such usage continues to grow as part of the much more general growth of the current information highway.
The World Wide Web was conceived by Berners-Lee in March 1989 (CERN, 1994) as a "hypertext project" to organize documents at CERN in an information retrieval system (Berners-Lee and Cailliau, 1990). The design involved: a simple hypertext markup language; distributed servers running on machines anywhere on the network; and access through any terminal, even line mode browsers. The web today still conforms to this basic model. Major usage began to grow with the February 1993 release of Andreessens (1993) Mosaic for X-Windows. Whereas the original web proposal specifically states it will not aim to "do research into fancy multimedia facilities such as sound and video" (Berners-Lee and Cailliau, 1990), the HTTP protocol for document transmission was designed to be content neutral and as well-suited to multimedia material as to text. The availability of the rich X-Windows graphic user interface on workstations supporting color graphics and sound led naturally to multimedia support, although the initial objective of meaningful access through any terminal was retained. Much web material can still be browsed effectively through a line mode browser.
In March 1993 the web was still being presented (Berners-Lee, 1993) as primarily a hypermedia retrieval system, but in November that year a development took place that so changed the nature of the web as to constitute a major new invention in its own right. Andreessen (1993) issued NCSA Mosaic version 2 using Standard Generalized Markup Language (SGML) tags (Goldfarb, 1990) to encode definitions of Motif widgets embedded within a hypermedia document, and allowed the state of those widgets within the client to be transmitted to the server. Suddenly the web protocols transcended their original conception to support graphic users interfaces providing access to interactive, distributed, client-server information systems (Rice, Farquhar, Piernot and Gruber, 1996). This change was again serendipitous since the original objective of the design had been to enable the user to specify retrieval information in a dialog box that was embedded in a document rather than in a separate window. However, the solution generalized from an embedded dialog box to any Motif widget including buttons, check boxes and popup menus. The capability of the user to use a web document to communicate with computer services allows active documents to be published on the web that, for example, provide data analysis, animation and simulation, and hence offer major new capabilities for scholarly communication.
An October 1995 survey (CommerceNet, 1995) estimates that 8% (18M) people aged 16 or above in North America had used World Wide Web in the previous 3 months. The Lycos (1995) search robot had indexed 10.75M documents in October 1995 which was estimated to be 91% of the total web corpus, and the overall growth rate of documents published on the web was over 1000% in 1995. The growth rate of overall Internet traffic is some 100% a year. However, web traffic was growing at some 1,000% a year when last accurately measured using NSFNET statistics for 1993/94. The growth of web traffic is widely recognized as a major impediment to its effective application, and a number of commercial services developed to operate through the web have been discontinued because the current infrastructure cannot sustain the traffic (Bayers, 1996).
The growth of the web relative to all the other services is apparent if one plots the proportion of the data accounted for by each service. The Merit statistics can be used through to their termination in April 1995 on the assumption that the relative traffic on the original backbone is representative of that on the whole Internet after November 1994. Figure 2 shows the proportion of FTP, web (HTTP), Gopher, News, Mail, Telnet, IRC and DNS data on the NSFNET backbone from December 1992 through April 1995. It can be seen that the proportion of all services except FTP and HTTP remain relatively constant throughout the period, declining slightly towards the end. However, the proportion attributable to FTP decreases while that due to the web HTTP protocol increases and becomes greater than that through: IRC in October 1993; Gopher in March 1994; mail in July 1994; news in November 1994; and FTP in March 1995. This corresponds to the basic web protocol becoming the primary carrier of net data traffic with a 25% and growing share when last measurable.
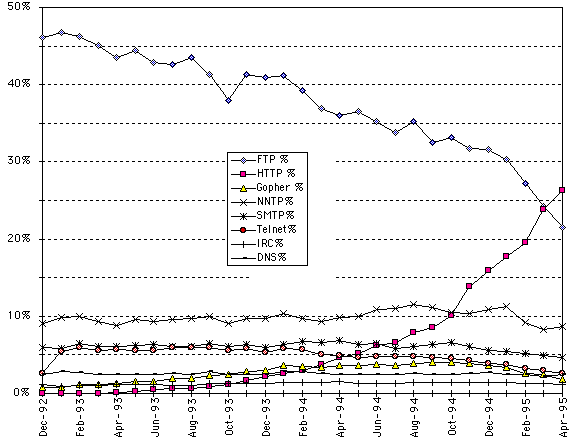
Figure 2 Proportion of FTP, web (HTTP), Gopher, News (NNTP), Mail (SMTP), Telnet, IRC and DNS traffic on the NSFNET backbone 1992-1995
It should be noted that one factor in the growth relative to other services is that the web traffic consists of large documents with embedded graphics. These statistics do not indicate that the number of web transactions exceeds the number of email transactions. It should also be noted that web browsers typically support many of the protocols shown including FTP, Gopher and News, but their usage of these protocols will show up under those protocols in the statistics. The crossover of web and FTP curves in Figure 2 shows a transition in the servers being primarily accessed, from FTP servers to web HTTP servers.
The exponential growth to ubiquity of access of the net and web are quantitative measures of the fundamental utility of the services provided, especially when one notes it was that growth that led to public awareness of the significance of the information highway. Internet access and usage has grown because it satisfies a needthere was very little marketing of the services during the basic growth period. However, this organic growth with little central direction has also meant that the human factors of the net and web have not been studied in depth, particularly those concerned with the social aspects of the effective formation and operation of the diffuse social communities that function through the net.
In examining the utility of the net and web it is useful to classify all the major services in terms of the significant distinctions that determine their relative utilities as shown in Figure 3 which characterizes the major net services in terms of their utility for computer-mediated communication, access to services or search. It sub-classifies such communication in terms of whether it is individual-to-individual discourse or community discourse; synchronous with the participants conversing in real time or asynchronous with substantial time delays in responses. It sub-classifies asynchronous community discourse by whether the channel is slow or fast, and whether the community is centrally registered or not. It sub-classifies service access in terms of whether it is: publication or interaction; presented or just fetched; text or rich media. It sub-classifies search by whether it is: indexing communication or services; by resource name or content; by keywords or by change in contents; and whether index terms are generated manually or automatically.
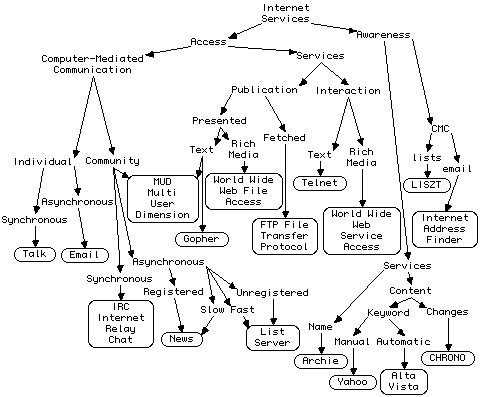
Figure 3 Distinctions characterizing the utility of various Internet services
The major services classified are:-
Talk, the facility for one user to send a message directly to the terminal of another user. This provides individual, synchronous computer-mediated communication.
Email, the facility for one user to send a message to the mailbox of another user. This provides individual, asynchronous computer-mediated communication.
Internet Relay Chat (IRC), the facility for a user to join a chat group and send a message directly to the terminals of the group. This provides community, synchronous computer-mediated communication.
News, the facility for a user to mail a message to a registered newsgroup archive and to access messages in the archive. This provides community, asynchronous computer-mediated communication. Because the archives are maintained on a local server and updated through a chain of servers the updating is slow, possibly taking several days.
List Server, the facility for a user subscribe to a list server and mail a message to it which it mails to all members on the list. This again provides community, asynchronous computer-mediated communication. Because the mailing to the list is fast (except for moderated groups where the mail is manually checked), list servers provide more interactive discourse than news groups. However, the registration of news groups makes them easier to discover, and, for high-volume discourse, users may prefer that it is not posted to their mailbox.
Multi-User Dimension (MUD), the facility for a user to enter a dimension, communicate directly with others there, and leave and retrieve documents. This provides community, computer-mediated communication and text resource access.
Gopher, the facility for a user to retrieve a text document from a hierarchically structured archive.
World Wide Web file access, the facility for a user to retrieve multi-media documents from an archive through hypertext links embedded in the document.
Telnet, the facility for a user to interact with a remote machine through a console window providing a command line interface. This provides remote interactive access to services providing textual interaction.
World Wide Web service access, the facility for a user to enter information into an HTML form and transmit it to a remote server. This provides remote interactive access to services providing rich media interaction.
File Transfer Process (FTP), the facility for a user to retrieve a file by site and name. This provides general file access but FTP clients generally lack the capability to present the files retrieved.
Internet Address Finder, a service for a user to search for the email address of a person by their name. One of the problems of the net is the lack of an overall directory of users.
LISZT, a service for a user to search for a list server by its name. This attempts to overcome the problem that there is no central directory of list servers.
Archie, a facility for a user to search the net for files by name. This provides search facilities for files with known names.
Yahoo, a facility for a user to search the net for resources by name and key word through a manually entered classification. This provides search facilities for resources specified by their name or type.
Alta Vista, a facility for a user to search the net for resources by content. This provides search facilities for resources with specified content.
CHRONO, a facility for a user to search a site through a list of changed resources in reverse chronological order. This provides search facilities for resources by recency.
Section 3 has measured the utility of the Internet and World Wide Web in terms of their widespread utilization, and Section 4 has characterized the various services in terms of their utility. The following sections develop a model of utility, usability and likeability by characterizing the discourse protocols involved in terms of their layers, temporal structure and the mutual awareness of participants in the discourse.
The human factors framework for the net and web as outlined in Section 1 can be analyzed in greater depth by using the layered protocol models which have been developed to provide a conceptual framework for complex systems of people and computing services (Gaines, 1988). Figure 4 shows a 6 layer model that partitions each sub-system, person or computing service, into:
A cultural layer which encompasses the milieu of the community within which the system operates and influences user intentionsBakhtins voices of the mind (Wertsch, 1991);
An intentionality layer which encompasses the objectives of the agents operating within the systemDennetts (1987) intentional stance;
A knowledge layer which encompasses the overt background knowledge necessary to translate agent intentions into actionsNewells (1982) knowledge level;
An action layer which encompasses the skills or services of the agents as they translate intentions into actions and communicationsMischels (1969) human action;
An expression layer which encompasses the encoding of actions or communications into a specific sequence of discrete actsthe neurobehavioral expression of action (Isaacson and Spear, 1982).
A physical layer which encompasses the encoding of actions into physical effects.

Figure 4 Layered protocol model for human-computer interaction
The action and expression layers are separated to allow actions to be conceptualized both as unitary abstractions and as the particular expression of those abstractions as a sequence of acts. For example auto-dialing may be conceived as a single psychological entity even though it may be expressed by a menu selection, dialog box click or command line text entry.
The term agent is used to cover both human users and computer services. At the current state of the art, the top three layers are design time considerations in developing computer services and only the three low levels are operational at run time, although the development of knowledgeable agents as a computer technology is a major research area.
Multiple 6 layer models of users and 3 layer models of services may be combined to provide a model of a complex system in which users communicate with other users and services through a network at the physical layer, establishing virtual circuits at the upper layers (Gaines, 1988). This is shown as "resource access" at the bottom of Figure 4 which subsumes the functionality that the agent can access through the network.
Shackels utility can now be seen as an evaluation of the extent to which a users intentions can be realized through processes accessing functionality available. For the net and web it is also appropriate to assess functionality in relation to a communitys needs.
Shackels usability can be seen as an evaluation of the extent to which users can translate their intentions into effective actions to access the functionality. It factors through 4 layers into:-
Knowledge issues concerned with the background knowledge that the user has available through experience or training;
Skills issues concerned with the users capability to translate intentions into actions using the background knowledge as appropriate;
Interface issues concerned with the facilities provided for the user to translate abstract actions into a sequence of acts;
Access issues concerned with the provisions for the user to access the functionality specified through the sequence of acts.
Shackels learnability, flexibility and likeability are non-functional aspects of usability that are manifest in each layer. Likeability is the least studied of the three because it has seemed a subjective matter with no behavioral model that can only be tested through questionnaire techniques. However, in recent years Csikszentmihalyis (1990) concept of flow as the phenomenon underlying the psychology of optimal experience has been applied to modeling user satisfaction with computer-mediated communication (Trevino and Webster, 1992). In their application of the model to flow phenomena in interaction with the web, Hoffman and Novak (1995) summarize the concept as:-
"Flow has been described as the process of optimal experience achieved when a sufficiently motivated user perceives a balance between his or her skills and the challenges of the interaction, together with focused attention. Flow activities in the Web, specifically network navigation, facilitate concentration and involvement because they are distinct from the so-called paramount reality of everyday existence."
It is reasonable to propose that likeability correlates with a flow state in which a motivated user undertakes a task whose level of difficulty is at some particular level that suits their individual needs. Too low a level results in boredom and too high a level in anxiety, and the optimal level results in the intense satisfaction with the activity that Csikszentmihalyi terms flow.
In the flow model, likeability is not associated with a particular layer of the protocol but rather with the appropriate level of activity involving the protocol. This explains some of the paradoxical aspects of usability analysishigh usability does not imply high likeability, and many well-liked interfaces and systems are poor from a usability standpoint. From a flow perspective, a simple task which is boring through a highly usable interface may be enhanced in its likeability by decreasing the interface usability to present a greater challenge to the user.
Similar considerations apply to flexibility which generally increases utility but may decrease usability because it involves the use of the system in modes for which it was not designed. The dimensions of human factors evaluation are not monotonically related and there are generally trade-offs between them.
The human factors of email may best be understood by contrasting it with similar communications through the telephone (Pool, 1977). The phone is essentially synchronous and when the phone rings the caller is generally unknown and it is too late once the information is known to decide whether the call should be answered or not. Caller information or filtering through a secretary or answering machines improve the situation, but if the decision is not to answer instantly then arrangements have to be made to call back. Email is attractive because it is asynchronous and replies can be prioritized on the basis of full information with a simple facility to call back. For professionals faced with substantial personal resource allocation problems, email has proved a very effective substitute for the telephone. It has the additional advantage that all discourse may be archived and indexed for later retrieval.
However, the volume of email may in itself become a problem, and the flow model may be applied to the likeability of email. New users of email may find it very attractive due to the reasons noted above but if few colleagues use it they will become bored with it and cease to use it. However, at the other extreme for an initially satisfied user as the volume grows it may reach a level where the challenge of dealing with it exceeds the users capacity and causes such anxiety that they again cease to use it. For high volume users, tools to automatically filter and archive email are very important.
Internet News is also a valuable resource but again the volume of news can be overwhelming if the user interface is inadequate. Good news readers provide simple mechanisms for printing and filing interesting news items similar to those of a mail reader. Because news access is under the control of the user it does not have the flow problems noted for email, and because the volume and diversity of news groups is so high it is easy for users with effective browsers to adjust the access to an optimal level and achieve a state of flow. This is probably the reason why news reading is commonly regarded as addictive.
Significant usability problems have arisen in existing Internet technology. For example, a usability problem has been introduced into the operation of list servers by the use of email browsers to access them. Because of the length and complexity of the information, mail browsers generally show only abbreviated headers which are adequate for normal mail but problematic for mail from list servers. This is because the servers use a simple trick to allow a reply to a message from the list to be addressed to the list rather than to the originator. The Internet mail protocol allows both a "From:" field and a "Reply-To:" field to be specified in the mail header. In normal mail usage the "Reply-To:" field is absent and a reply is sent to the address in the "From:" field. In list servers the "From:" field is filled with the originator and the "Reply-To:" field is filled with the list server address so that replies go to the list. However, email browsers generally show the "From:" field as the origin of the mail, and it appears to the user as if they are replying to the individual who sent the mail to the list. This often leads to embarrassingly personal messages intended only for one person being mailed to the entire list. It would be better if email browsers were configured to show the "Reply-To:" field in preference to the "From:" field, perhaps indicating that the "From:" field is different.
Some list administrators set the "Reply-To" field to be the originator to avoid this problem, but this reduces the usability of the interface since most replies are intended for the community, and having to enter the list server address in a reply is an impediment to spontaneous discourse. Some list administrators overcome the problem by "moderating" their lists and examining each item of mail before authorizing it to go to the list. This is again a serious impediment to discourse since it introduces delays, taking the list turnaround time from minutes to days.
The usability problems created by email browsers failure to represent the "Reply-To:" field adequately, and by attempts to fix this, may be seen as a conflict between the knowledge and skills layers in the layered protocol model. The user is required to disrupt the skilled activity of discourse by a knowledge-driven override. Email discourse is similar to vocal discourse in that when a person receives a message they may instantly conceive a reply. The emission of the reply vocally is mediated automatically without disruption of the chain of consciousness framing the reply. Hitting the "Reply" key in an email browser is a similar subconscious reaction made automatically without disruption of the process of composing a reply. However, having to remember or ascertain whether the reply is going to the originator or the list, and manually fix the address if it is not what is wanted, disrupts the composition of a reply.
The problems may also be seen as arising from the flexibility of the email browsers which enables them to be used as list server browsers. Flexibility is generally positive for utility because it widens the range of applications, but it is often negative for usability in that it involves operating the system outside the range of situations for which it was designed to be usable.
The web has similar likeability characteristics to news since it offers a much richer variety of material with access under user control. The complexity of the services offered through the web leads to many usability issues which cannot be detailed in this article. Web document preparation and browsing involve some eight major issues:
Graphic user interfaces subject to the guidelines that have been developed over the years. The usual issues of uniformity in style of layout, presentation, vocabulary, use of color, and so on apply, and human factors design may be modeled on existing practice (Shneiderman, 1983; Smith and Mosier, 1986; Shackel and Richardson, 1991).
Typography, layout and visualization which have human factors guidelines arising in graphic design and information visualization (Bertin, 1983; Tutte, 1990).
Hypermedia navigation where issues such as cognitive overload in hyperspace navigation, and the associated guidelines, are also becoming well-defined in the hypertext community (Conklin, 1987; McKnight, Dillon and Richardson, 1991).
HTML writing skills required to create a web document involve concepts that are foreign to users experienced with WYSIWYG word processors.
Indexing and tracking changes in the large and changing corpus of documents available through the web.
Communication delays which can be long and variable, and are crucially dependent on features of the data structures and client architecture. System designers need to be aware of far more detail about the web operation than is apparent at first sight.
Integration with other applications which can present or process the many file types accessible across the web that are not directly presentable by the web browser.
Interaction with active documents offering web services going beyond document presentation to offer client server interaction with a range of complex applications.
The cultural layer at the top of Figure 4 itself requires partitioning when one considers the different forms of community supported through computer-mediated communication. At least three types of community need to be distinguished: the highly-coordinated, goal-directed teams; the more loosely coordinated special-interest communities, such as professional sub-disciplines; and the largely uncoordinated Internet world at large whose members have in common only the use of computer-mediated communication. Figure 5 shows the layered protocol model extended to groups of agents distinguished in this way.
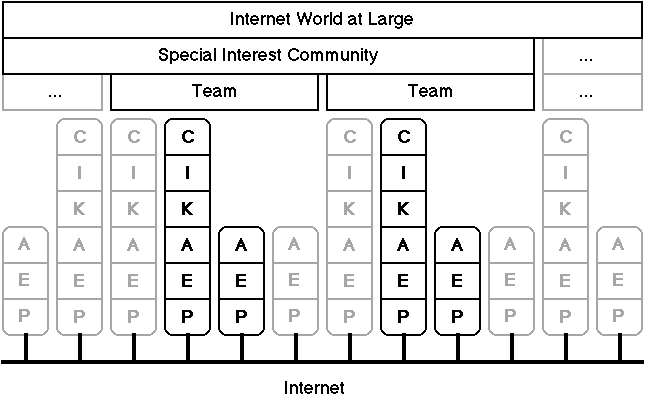
Figure 5 Communities within the layered protocol model
(3
layers represent computer services and 6 layers users,
gray items represent
an indefinite iteration)
For purposes of human factors analysis one needs a precise behavioral definition of these various form of community. How may they be differentiated conceptually and through empirical observation? One can regard a community as a set of individuals that provide resources to one another with the most significant dimension relating to the coordination of the community being that of the awareness of who is providing a particular resource and who is using it. In the tightly-coupled team, each person is usually aware of who will provide a particular resource and often of when they will provide it. In logical terms, this can be termed extensional awareness because the specific resource and provider are known, as contrasted to intensional awareness in which only the characteristics of suitable resources or providers are known.
A team can be treated from a collective stance (Gaines, 1994) as a single psychological individual that behaves as a compound role generated by the distributed activities of roles in a number of people. Each resource provider in a team has an extensional awareness of their actual resource users, and each resource user has an extensional awareness of the resource and who will provide it.
In a special interest community resource providers usually do not have such extensional awareness of the resource users, and, if they do, can be regarded as forming teams operating within the community. Instead, resource providers usually have an intensional awareness of the resource users in terms of their characteristics as types of user within the community. The classification of users into types usually corresponds to social norms within the community, such as the ethical responsibilities in a professional community to communicate certain forms of information to appropriate members of the community. Resource users in a special interest community may have an extensional awareness of particular resources or resource providers, or an intensional awareness of the types of resource provider likely to provide the resources they require. This asymmetry between providers and users characterizes a special interest community and also leads to differentiation of the community in terms of core members of whom many users are extensionally aware, and sub-communities specializing in particular forms of resource.
In the community of users at large, there is little awareness of particular resources or providers and only a general awareness of the rich set of resources is available. Awareness of the characteristics of resources and providers is vague, corresponding to weak intensional awareness.
These distinctions lead to human factors consequences in terms of the appropriate awareness mechanisms that need to be established on the network for the communities to function. In a team, resources may be identified precisely by location and name. In a special-interest community, resources may be identified by an intensional indexing scheme that classifies them in terms of the distinctions made by that community. In the community of users at large, resources may be identified both by indexing their content type using a wide variety of taxonomies and by indexing their actual content.
These distinctions are summarized in Figure 6, and it is apparent that the classification of awareness can lead to a richer taxonomy of communities than the 3-way division defined. Analysis of awareness in these terms allows the structure of a community to be specified in operational terms, and in complex communities there will be complex structures of awareness. The coarse divisions into sub-teams and sub-special interest communities provides a way of reducing this complexity in modeling the community.
|
Team |
Special-Interest Community |
Community at Large | |
|
Resource Provider |
Extensional awareness of actual users. |
Intensional awareness of types of users. |
No awareness of users, or only weak intensional awareness of types of users. |
|
Resource |
Extensional awareness of actual resources and providers. |
Extensional awareness of actual resources and providers, or intensional awareness of types of resources and providers. |
No awareness of resources or providers, or only weak intensional awareness of types of resources and providers. |
Figure 6 Communities distinguished by awareness
The community structure of discourse through list servers may be studied through statistical analysis of the server archives, and shows that a small group of members generally dominate the discourse. Figure 7 shows the number of items, number of different contributors, number of contributors with 5 or more mailings, and the group of authors who account for 50% of the total mailings to the list for the conceptual graphs list server (Gaines, 1993b). This list commenced in August 1989 serves a community of some 220 researchers concerned with knowledge representation based on Sowas (1984) work, and Sowa was himself a major contributor during its formative years. It can be seen that between 4 and 13 members of the community account for over 50% of the items mailed, and that this group is consistent over the 3 year period studied.
|
Year |
1990 |
1991 |
1992 |
1993 |
1994 |
1995 |
|
Total number of items |
270 |
325 |
607 |
720 |
1040 |
396 |
|
Total number of authors |
37 |
63 |
125 |
168 |
213 |
108 |
|
Number authors with 5 items |
14 |
13 |
24 |
27 |
49 |
22 |
|
Number of authors accounting for 50% of items |
4 |
4 |
8 |
11 |
13 |
11 |
Figure 7 Patterns of contribution to a list server
This pattern of behavior shown in Figure 7 is typical of most special interest communities where a relatively small number of facilitators both introduce topics and respond to most discussion items introduced by others. The small group has extensional awareness within itself and often acts as a team, whereas it has only intensional awareness of the types of background of other members on the list. There are strategies which allow facilitators to ensure that those posting discussion items have the satisfaction of seeing responses, yet attempt to reduce the dominance of the facilitators, for example by deliberately introducing a delay of a few days in their own responses to encourage others to respond instead of them. However, in some cases it is apparent that the person introducing a discussion item is hoping for a response from an extensionally defined particular person and this strategy would then be inappropriate.
The human factors of list server interactions merit much more detailed study than they have received to date. Bales and Cohens (1979) SYMLOG methodology, based on Bales (1950) deep analysis of small group dynamics, provides an appropriate methodology. He classifies communications along three major dimensions: dominantsubmissive, friendlyunfriendly, and instrumentalemotional. To these may be added a classification of the focus of discourse, whether to a specific individual or the group, and a content analysis of the memetic processes of developing a particular knowledge product.
Losada, Sanchez and Noble (1990) have used an extended SYMLOG methodology to classify detailed observations of small groups working together around a table, and have developed computational time series analyses which, presented in graphical form, clearly model the groups behavior and show dysfunctional modes of operation. A similar approach to the analysis of list server archives would provide empirical data on the human factors of discourse in computer-mediated communication.
The differentiation of communities in terms of awareness also draws attention to the significance of supporting various aspects of awareness in a computer-mediated communication system. As noted above resource awareness, the awareness that specific resources or resources with specified characteristics exists, may be supported by various indexing and search procedures. However, there is also a need to support chronological awareness (Chen and Gaines, 1996), the awareness of when a resource has changed or come into existence. These are major human factors issues in users coping with the net as a rich and rapidly changing system of resources.
The layered protocol model applied to communities, coupled with the differentiation of those communities in terms of awareness of resources provides a simple, yet adequate, conceptual framework for the analysis of the cognitive and social human factors of the net and web. The following section extends the model to encompass temporal behavior.
The distinctions made in Figure 3 present Internet services in terms of their utility, but do not provide an integrative model of the way in which they support communities. Such a model can be developed by considering the temporal patterns of discourse in the layered protocol model of Figure 5. What distinguishes computer-mediated communication from publication is that in computer-mediated communication it is expected that the recipient will respond to the originator, whereas publication is generally a one-way communication. However, on list servers some material is published in that the originator expects no specific response, and material published in electronic journals or archives often evokes a response. The net and web offer a very flexible medium that breaks down the conventions of other media. The following diagrams show the different characteristics of the main Internet services in terms of these issues.
Figure 8 shows email discourse as a cycle of origination and response between a pair of agents communicating through a computer-mediated channel.
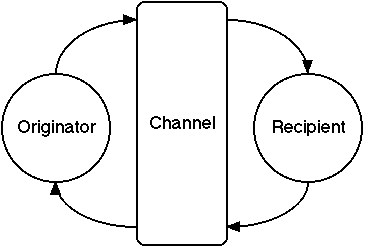
Figure 8 Email discourse
Figure 9 extends Figure 8 to show list server discourse as a cycle of origination and response between agents that is shared with a community through a computer-mediated channel. The community involvement leads to more complex discourse patterns in that: the originator may not direct the message to a particular recipient; there may be multiple responses to a message; and the response from the recipient may itself trigger responses from others who did not originate the discourse. For a particular discourse sequence this leads to a natural division of the community into active participants who respond and passive participants who do not.
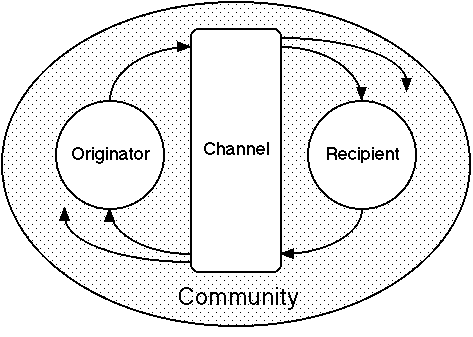
Figure 9 List server discourse
Figure 10 modifies Figure 9 to show web publication as an activity in which the channel is buffered to act as a store also. The material published is available to a community and the originator is unlikely to target it on a particular recipient. Recipients are not expected to respond direct to the originator, but responses may occur through email, list servers or through the publication of material linked to the original. Because the published material is not automatically distributed to a list, recipients have to actively search for and discover the material.
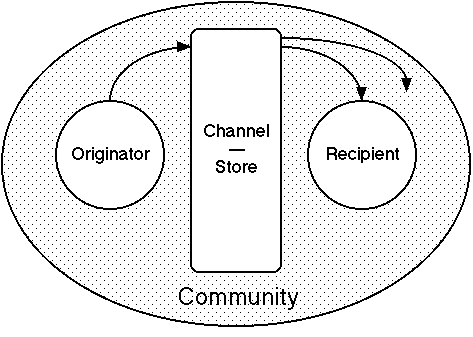
Figure 10 World Wide Web publication
The common structure adopted for the diagrams is intended to draw attention to the commonalities between the services. List server discourse is usually archived and often converted to hypermail on the web. Web publications do trigger responses through other services or through links on the web. A search on the web may not discover a specific item but rather a related item on a newsgroup, list or by an author, and result in an request for information to the newsgroup, list or author. Individuals and communities use many of the available Internet services in an integrated way to support their knowledge processes.
Figure 11 subsumes Figures 8 through 10 to provide an integrated model of the temporal structure of Internet communication processes that captures all the issues discussed. It models the processes as discourse punctuated by the intervention of a store allowing an indefinite time delay between the emission of a message and its receipt. It introduces two major dimensions of analysis: the times for each step in a discourse cycle; and the awareness by originators of recipients and vice versa.
The four times shown in Figure 11 are:
t1: the origination timethe time from a concept to its expression and availability
t2: the discovery timethe time from availability to receipt
t3: the response timethe time from receipt to expression and availability of a response
t4: the response discovery timethe time from response availability to receipt
Note that agent processing times and channel delays have been lumped. A study focusing on the impact of communication delays would want to consider them separately, otherwise there is no significant distinctiona general principle might be that communication delays should not be greater than agent processing times. Note also that the diagram is to a large extent symmetricalthe recipient becomes an originator when responding.
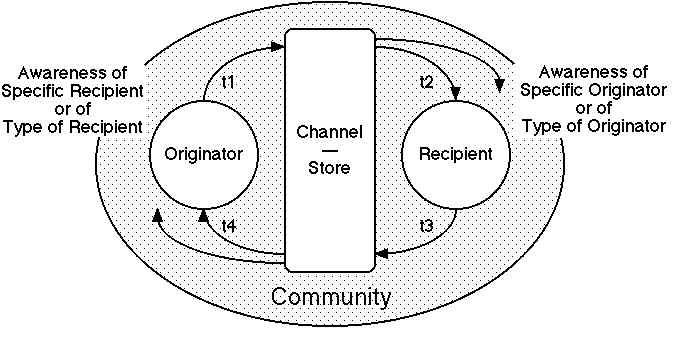
Figure 11 Punctuated discourse
An important overall parameter is the round-trip discourse time, t1+t2+t3+t4. If this is small, a few seconds or less, we talk in terms of synchronous communication. If its is large, a few hours or more, we talk in terms of asynchronous communication. If it is infinite, so that there is no response, we talk in terms of publication. However, this analysis shows that there is a continuous spectrum from synchronous through asynchronous to publication.
The discovery times, t2 and t4, are very significant to publication-mode discourse, and attempts to reduce them have led to a wide range of awareness-support tools that aid potential recipients to discover relevant material and originators to make material easier to discover.
The origination and response times, t1 and t3, need to be similar if the discourse is to be likeable. A respondent with a significantly shorter processing time than average will become bored because the community is not originating problems sufficiently rapidly to be challenging, whereas one with a significantly longer processing time than average will feel pressured by a too rapid flow of inputs.
In scholarly discourse, the discourse times may range over some 11 orders of magnitude from seconds to millenia. An individual may undertake a lifetime of research in order to respond to a fundamental question. The continuing impact of the Greek enlightenment on philosophical scholarship illustrates how members of community may continue to respond to arguments posed over two thousand years ago.
The characterizations of Internet communities in terms of awareness (Section 6) and time cycle of interaction (Section 7) may be combined to provide a plot (Figure 12) of the major services defined in Section 3.
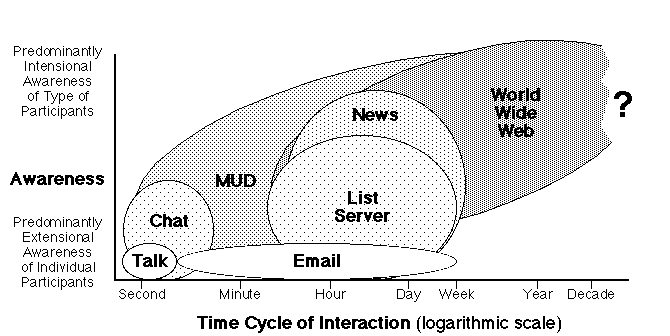
Figure 12 Internet services classified in terms of awareness and time cycle
Figure 12 shows talk and email involving extensional awareness of the individuals involved but with the email cycle time being longer, corresponding to talk being synchronous but email asynchronous. The figure makes it clear that it is important to think of the degree of synchronity as an analog dimension not a binary distinction. Chat is shown as overlapping talk but usually involving some lesser awareness of other participants and longer time cycles in discourse.
List servers and news groups operate on time cycles of hours to days and involve extensional awareness of only a few participants but reasonably strong intensional awareness of the type of participant. The web operates on even longer time scales from a day up to years and generally involves little extensional awareness of participantsreaders may know particular authors, but writers generally do not know their readers. The question mark indicates that the web has been operating for such a short period that any long term estimates of its impact as a publication medium are speculative projections.
MUDs, as noted previously, are anomalous in combining chat- and web-like services, and span a major part of the plot. This may seem strange in that they are not ubiquitous like the other services shown, although there are significant uses of MUDs to support professional communities (Curtis, 1993; Curtis and Nichols, 1993; Evard, 1993). However, web browsers are being extended to integrate the chat facilities of MUDs as well as providing access to email, news, new collaborative tools and audio-visual interaction. Hence, as happened to Gopher, the web is subsuming MUDs and the entire spectrum of services shown in Figure 12 will appear to the end-user as an integrated service. However, the human factors distinctions between the different forms of discourse being supported will remain.
The Internet and World Wide Web have already established themselves as major factors in the operation of scholarly communities world wide. The discourse processes underlying scholarly communication have come to rely on paper media and physical meetings, and have remained relatively unchanged for some 300 years. They are now undergoing revolutionary changes that necessitate a fundamental re-evaluation of our models of those processes and the ways in which they can be supported.
However, the growing role of computers in scholarship should not distract us from the fact that it is the human factors of scholarship that continue to dominate its processes. The role of computers, digital media and telecommunications is to support human knowledge processes, and the impact of new technologies can only be understood in terms of their human factors, their utility in supporting scholarship, their usability in making this support simply available, and their likeability in making it an attractive task.
The human factors involved are not only those of the individual carrying out specific tasks using the technologies, but also the socio-cultural factors of the communities that operate through the net: goal-directed teams, special-interest communities and the Internet world at large. Tools have to be evaluated in terms of their utility in supporting the knowledge processes of communities as well as their usability for individuals.
This article has distinguished the major services on the net in terms of dimensions of utility such as: resource access or awareness; access to computer-mediated communication or services; synchronous or asynchronous communication; support of text or rich media; search by name or by content; and so on.
A foundational model for the analysis of the human factors of the net and web has been developed in terms of a layered protocol model for human-computer interaction and its application to communities operating on the net distinguished by their different forms of awareness. The temporal characteristics of discourse on the Internet have been used to provide an integrated model of Internet services in terms of the two dimensions of cycle time and awareness. Likeability and usability aspects of some of the major services have been analyzed in terms of the model.
The article is long yet leaves much unsaid. The net and web and the activities they support are vast, and any comprehensive account would have to be encyclopedic in scope. Hopefully, the framework provided will be useful to those needing to understand the net and web and their impacts on scholarship, to those needing to plan the application of these technologies within their institutions, and to those developing tools to support those participating in this massive enterprise. Hopefully also it will encourage studies to quantify the phenomena involved. We need to understand the processes of scholarship at an overt level and to a depth never before necessary or possible. Fortunately the net itself instruments many of the processes of scholarship and provides us with a wealth of empirical data which will form the basis of increasingly comprehensive models of knowledge processes in human society. In the long term this may come to be seen as the greatest impact of the use of the information highway to support scholarly activities.
Financial assistance for this work has been made available by the Natural Sciences and Engineering Research Council of Canada. We are grateful to Andrew Dillon for his advice and encouragement and to the anonymous referees for critical comments that have substantially improved the paper.
Ackerman, M.S. (1994). Augmenting the organizational memory: a field study of answer garden. Proceedings of the Fifth Conference on Computer-Supported Cooperative Work. pp.243-252. New York, Association for Computing Machinery.
Aiken, R., Braun, H.-W., Ford, P. and Claffy, K. (1992). NSF Implementation Plan for Interagency Interim NREN. NSF. gopher://nic.merit.edu:7043/0/cise/recompete/impl.ascii.
Allen, T.J. (1977). Managing the Flow of Technology: Technology Transfer and the Dissemination of Technological Information within the R&D Organization. Cambridge, MA, MIT Press.
Andreessen, M. (1993). NCSA Mosaic Technical Summary. NCSA, University of Illinois. ftp://ncsa.uiuc.edu/Web/Mosaic/Papers/mosaic.ps.Z.
Bales, R.F. (1950). Interaction Process Analysis. Chicago, University of Chicago Press.
Bales, R.F. and Cohen, S.P. (1979). SYMLOG: A system for the multiple level observation of groups. New York, Free Press.
Bayers, C. (1996). The great web wipeout. Wired 4(4) 126-128.
Berners-Lee, T. (1993). World-Wide Web Talk at Online Publishing 1993. CERN, Geneva. http://info.cern.ch/hypertext/WWW/Talks/OnlinePublishing93/Overview.html.
Berners-Lee, T. and Cailliau, R. (1990). WorldWideWeb: Proposal for a Hypertext Project. CERN, Geneva. http://info.cern.ch/hypertext/WWW/Proposal.html.
Bertin, J. (1983). Semiology of Graphics. Madison, Wisconsin, University of Wisconsin Press.
Burstein, D. and Kline, D. (1995). Road Warriors: Dreams and Nightmares along the Information Highway. New York, Penguin.
CERN (1994). History to date. CERN, Geneva. http://info.cern.ch/hypertext/WWW/History.html.
Chen, L.L.-J. and Gaines, B.R. (1996). Methodological issues in studying and supporting awareness on the World Wide Web. Maurer, H., Ed. Proceedings of WebNet96. Charlottesville, VA, Association for the Advancement of Computing in Education.
Claerbout, J. (1992). Electronic documents give reproducible research a new meaning. Expanded Abstracts of 62nd Annual International Meeting of Society for exploratory Geophysics. pp.601-604.
CommerceNet (1995). CommerceNet/Nielsen Internet Demographics Survey. CommerceNet. http://www.commerce.net/information/surveys/.
Conklin, J. (1987). Hypertext: An introduction and survey. IEEE Computer 20(9) 17-41.
Crane, D. (1972). Invisible Colleges: Diffusion of Knowledge in Scientific Communities. Chicago, University of Chicago Press.
Csikszentmihalyi, M. (1990). Flow: The Psychology of Optimal Experience. New York, Harper and Row.
Curtis, P. (1993). LambdaMOO Programmer's Manual. ftp://parcftp.xerox.com/pub/MOO/ProgrammersManual.ps.
Curtis, P. and Nichols, D. (1993). MUDs grow up: social virtual reality in the real world. Proceedings Third International Conference on Cyberspace. ftp://parcftp.xerox.com/pub/MOO/papers/MUDsGrowUp.ps.
Dennett, D.C. (1987). The Intentional Stance. MIT Press, Cambridge, Massachusetts.
Dreyfus, H.L. and Dreyfus, S.E. (1986). Mind over Machine: The Power of Human Intuition and Expertise in the Era of the Computer. New York, Free Press.
Evard, R. (1993). Collaborative networked communication: MUDs as systems tools. Proceedings LISA Conference. (ftp://parcftp.xerox.com/pub/MOO/papers/Evard.ps).
Floridi, L. (1995). Internet: which future for organized knowledge, Framkenstein or Pygmalion? International Journal Human-Computer Studies 43(2) 261-274.
Ford, J., Makedon, F. and Rebelsky, S.A., Ed. (1995). DAGS95: Electronic Publishing and the Information Superhighway. Berlin, Birkhäuser.
Gaines, B.R. (1971). Through a teleprinter darkly. Behavioural Technology 1(2) 15-16.
Gaines, B.R. (1988). A conceptual framework for person-computer interaction in distributed systems. IEEE Transactions Systems, Man & Cybernetics SMC-18(4) 532-541.
Gaines, B.R. (1993a). An agenda for digital journals: the socio-technical infrastructure of knowledge dissemination. Journal of Organizational Computing 3(2) 135-193.
Gaines, B.R. (1993b). Representation, discourse, logic and truth: situating knowledge technology. Mineau, G.W., Moulin, B. and Sowa, J.F., Ed. Conceptual Graphs for Knowledge Representation. pp.36-63. New York, Springer.
Gaines, B.R. (1994). The collective stance in modeling expertise in individuals and organizations. International Journal of Expert Systems 7(1) 21-51.
Gaines, B.R. (1995). Dimensions of electronic journals. Harrison, T. and Stephen, T.D., Ed. Computer Networking and Scholarly Communication in the Twenty-First Century University. pp.315-334. New York, State University of New York Press.
Goldfarb, C.F. (1990). The SGML Handbook. Oxford, Clarendon Press.
Harrison, T. and Stephen, T.D., Ed. (1995). Computer Networking and Scholarly Communication in the Twenty-First Century University. New York, State University of New York Press.
Hoffman, D.L. and Novak, T.P. (1995). Marketing in Hypermedia Computer-Mediated Environments: Conceptual Foundations. Journal of Marking to appear (July).
IBC (1995). Internet Business Statistics. Internet Business Center. http://tig.com/IBC/Statistics.html.
Isaacson, R.L. and Spear, N.E. (1982). The Expression of Knowledge: Neurobehavioral Transformations of Information into Action. New York, Plenum Press.
Kahin, B. and Abbate, J., Ed. (1995). Standards Policy for Information Infrastructure. Cambridge, MA, MIT Press.
Kahin, B. and Keller, J., Ed. (1995). Public Access to the Internet. Cambridge, MA, MIT Press.
Krol, E. (1993). FYI on "What is the Internet?". Internet. RFC 1462.
Losada, M., Sanchez, P. and Noble, E.E. (1990). Collaborative technology and group process feedback: their impact on interactive sequences in meetings. Proceedings of CSCW'90. pp.53-64. New York, ACM.
Lycos (1995). Lycos. http://www.lycos.com.
Matta, K.F. and Boutros, N.E. (1989). Barriers to electronic mail systems in developing countries. Information Society 6(1/2) 59-68.
McKnight, C., Dillon, A. and Richardson, J. (1991). Hypertext in Context. Cambridge, UK, Cambridge University Press.
McLuhan, M. and McLuhan, E. (1988). Laws of Media: The New Science. Toronto, University of Toronto Press.
Mischel, T., Ed. (1969). Human Action. New York, Academic Press.
Mitroff, I.I. (1974). The Subjective Side of Science. New York, Elsevier.
Newell, A. (1982). The knowledge Level. Artificial Intelligence 18(1) 87-127.
NW (1996). Internet Domain Survey. Network Wizards. http://www.nw.com.
Odlyzko, A.M. (1995). Tragic loss or good riddance? the impending demise of traditional scholarly journals. International Journal Human-Computer Studies 42(1) 71-122.
Peek, R.P. and Newby, B., Ed. (1996). Scholarly Publishing: The Electronic Frontier. Cambridge, Massachusetts, MIT Press.
Pool, I. S., Ed. (1977). The Social Impact of the Telephone. Cambridge, MA, MIT Press.
Popper, K.R. (1968). Epistemology without a knowing subject. Rootselaar, B. Van, Ed. Logic, Methodology and Philosophy of Science III. pp.333-373. Amsterdam, North-Holland.
Redi, J. and Bar-Yam, Y. (1995). InterJournal: A distributed refereed electronic journal. Ford, J., Makedon, F. and Rebelsky, S.A., Ed. DAGS95: Electronic Publishing and the Information Superhighway. pp.183-190. Berlin, Birkhäuser.
Rice, J., Farquhar, A., Piernot, P. and Gruber, T. (1996). Using the web instead of a window system. Proceedings of CHI'96. pp.103-117. New York, ACM.
Salus, P. (1995). Casting the Net: From ARPANET to INTERNET and Beyond. Reading. MA, Addison-Wesley.
Shackel, B. (1991). Usabilitycontext, framework, definition, design and evaluation. Shackel, B. and Richardson, S., Ed. Human Factors for Informatics Usability. pp.21-37. Cambridge, UK, Cambridge University Press.
Shackel, B. and Richardson, S., Ed. (1991). Human Factors for Informatics Usability. Cambridge, UK, Cambridge University Press.
Shea, V. (1994). Netiquette. San Francisco, Albion Books.
Shneiderman, B. (1983). Direct manipulation: a step beyond programming languages. Computer 16(8) 57-69.
Smith, S.L. and Mosier, J.N. (1986). Guidelines for Designing User Interface Software. Mitre Corporation. ESD-TR-86-278.
Sowa, J.F. (1984). Conceptual Structures: Information Processing in Mind and Machine. Reading, Massachusetts, Adison-Wesley.
Spears, R. and Lea, M. (1994). Panacea or panopticon? The hidden power in computer-mediated communication. Communication Research 21(4) 427-459.
Trevino, L.K. and Webster, J. (1992). Flow in computer-mediated communication. Communication Research 19(5) 539-575.
Tutte, E.R. (1990). Envisioning Information. Cheshire, Connecticut, Graphics Press.
Walther, J.B. (1992). Interpersonal effects in computer-mediated communication: A relational perspective. Communication Research 19(1) 52-90.
Wertsch, J.V., Ed. (1991). Voices of the Mind: A Sociocultural Approach to Mediated Action. Cambridge, MA, Harvard University Press.
Whissel, C.M. (1989). The dictionary of affect in language. Plutchik, R. and Kellerman, H., Ed. Emotion Theory, Research and Experience Volume 4. pp.113-131. San Diego, Academic Press.
Last update: 2002-03-27 by Lee Chen